Learning-based Inverse Subsurface Scattering
Subsurface Scattering
Translucent materials are everywhere around us, ranging from biological tissues to many industrial chemicals, and from the atmosphere and clouds to minerals. The common cause of the characteristic appearance of all these classes of materials is subsurface scattering: As photons reach the surface of a translucent object, they continue traveling in its interior, where they scatter, potentially multiple times, before reemerging outside the object. The ubiquity of translucency has motivated decades of research across numerous scientific fields on problems relating to subsurface scattering.
Efficient
More Info
We introduced inverse transport networks as an architecture that can combine the efficiency of neural networks with the generality properties of analysis by synthesis.
Physically Accurate
More Info
We demonstrate the effectiveness of our networks in experiments on synthetic and real datasets, where we show that our networks can use a single uncalibrated (completely unknown shape and illumination) image input, to produce material parameter estimates that are on average 38.06% more accurate than those produced by baseline regression networks. Furthermore, images rendered with our predictions are on average 53.82% closer to the groundtruth.
Deep Learning
More Info
We investigate the use of deep learning techniques for inverse scattering problems, as a means to address the computational challenges of analysis by synthesis, while maintaining its broad applicability.
Inverse Transport Network
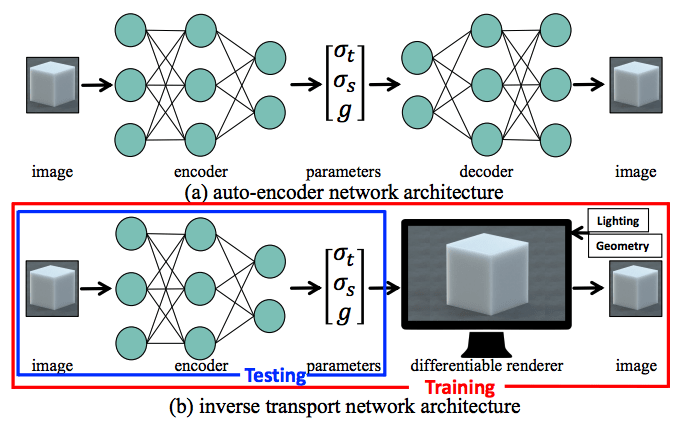
We introduce a new architecture, the inverse transport network (ITN), that aims to improve generalization of an encoder network to unseen scenes, by connecting it with a physically-accurate, differentiable Monte Carlo renderer capable of estimating image derivatives with respect to scattering material parameters. During training, this combination forces the encoder network to predict parameters that not only match groundtruth values, but also reproduce input images. During testing, the encoder network is used alone, without the renderer, to predict material parameters from a single input image. Drawing insights from the physics of radiative transfer, we additionally use material parameterizations that help reduce estimation errors due to ambiguities in the scattering parameter space. Finally, we augment the training loss with pixelwise weight maps that emphasize the parts of the image most informative about the underlying scattering parameters. We demonstrate that this combination allows neural networks to generalize to scenes with completely unseen geometries and illuminations better than traditional networks, with 38.06% reduced parameter error on average.

Fig. 3: Weight maps: We use per-pixel weights equal to each pixel’s distance from the nearest image edge, in order to emphasize image pixels where similarity relations are violated. also style every aspect of this content in the module Design settings and even apply custom CSS to this text in the module Advanced settings.



People

Chengqian Che
Fujun Luan
Shuang Zhao
Kavita Bala

Ioannis Gkioulekas