Langevin Monte Carlo Rendering


Fig. 1. Equal-time (20 minutes) comparison between MEMLT, MMLT, RJMLT, H2MC and two variants of our methods. The scene presents complex glossy and specular interreflections with difficult visibilities. The reference (Ref.) is rendered by BDPT in roughly a day.
Langevin Monte Carlo
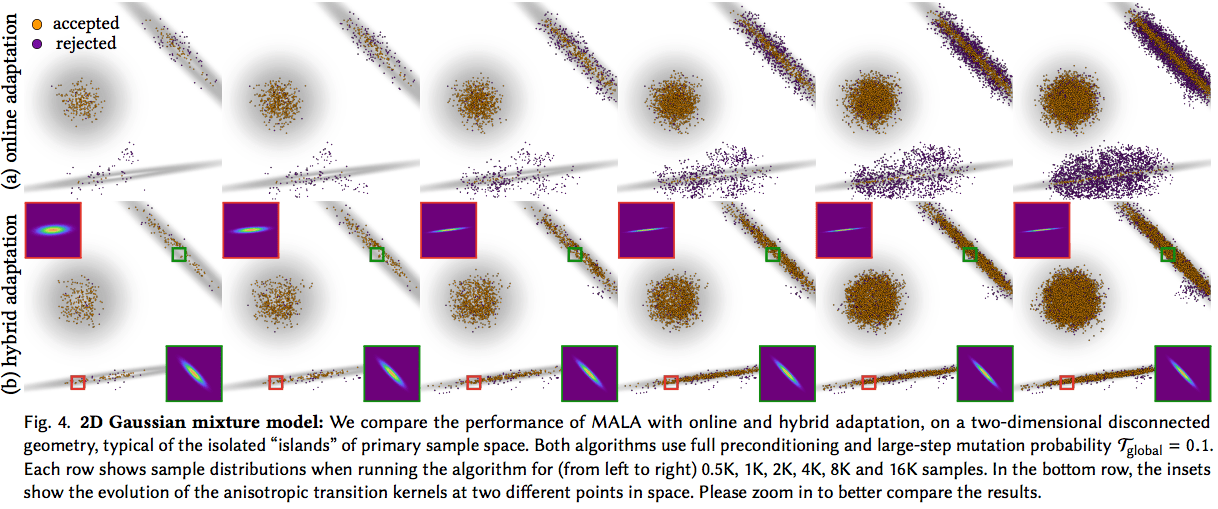
We introduce a suite of Langevin Monte Carlo algorithms for efficient photorealistic rendering of scenes with complex light transport effects, such as caustics, interreflections, and occlusions. Our algorithms operate in primary sample space, and use the Metropolis-adjusted Langevin algorithm (MALA) to generate new samples. Drawing inspiration from state-of-the-art stochastic gradient descent procedures, we combine MALA with adaptive preconditioning and momentum schemes that re-use previously-computed first-order gradients, either in an online or in a cache-driven fashion.
MALA with online and cache-driven adaptation
This combination allows MALA to adapt to the local geometry of the primary sample space, without the computational overhead associated with previous Hessian-based adaptation algorithms. We use the theory of controlled Markov chain Monte Carlo to ensure that these combinations remain ergodic, and are therefore suitable for unbiased Monte Carlo rendering. Through extensive experiments, we show that our algorithms, MALA with online and cache-driven adaptation, can successfully handle complex light transport in a large variety of scenes, leading to improved performance (on average more than 3× variance reduction at equal time, and 7× for motion blur) compared to state-of-the-art Markov chain Monte Carlo rendering algorithms.
Minimal Computational Overhead
More Info
We propose adaptation mechanisms that introduce minimal computational overhead compared to standard LMC. These include a Hessian approximation and a momentum vector that can be computed by performing only scalar operations on first-order gradients, sidestepping the need for expensive second-order differentiation and matrix operations.
New Caching Scheme
More Info
We combine these adaptation mechanisms with a new caching scheme, that stores previously computed gradients, and uses them to guide the sampling process in a way that facilitates both local and global exploration.
Low Error
More Info
This project results in three MCMC rendering algorithms that significantly outperform state-of-the-art techniques, resulting in an average MSE improvement of 3× on equal-time comparisons across a large variety of challenging scenes, and 7× for scenes with motion blur.



People
FUJUN LUAN
SHUANG ZHAO
KAVITA BALA

IOANNIS GKIOULEKAS